Learn How to Build True Edge Apps With Cloudflare Workers and Fauna
September 23, 2021There is a lot of buzz around apps running on the edge instead of on a centralized server in web development. Running your app on the edge allows your code to be closer to your users, which makes it faster. However, there is a spectrum of edge apps. Many apps only have some parts, usually static content, on the edge. But you can move even more to the edge, like computing and databases. This article describes how to do that.
Intro to the edge
First, let’s look at what the edge really is.
The “edge” refers to locations designed to be close to users instead of being at one centralized place. Edge servers are smaller servers put on the edge. Traditionally, servers have been centralized so that there was only one server available. This made websites slower and less reliable. They were slower because the server can often be far away from the user. Say if you have two users, one in Singapore and one in the U.S., and your server is in the U.S. For the customer in the U.S., the server would be close, but for the person in Singapore, the signal would have to travel across the entire Pacific. This adds latency, which makes your app slower and less responsive for the user. Placing your servers on the edge mitigates this latency problem.

With an edge server design, your servers have lighter-weight versions in multiple different areas, so a user in Singapore would be able to access a server in Singapore, and a user in the U.S. would also be able to access a close server. Multiple servers on the edge also make an app more reliable because if the server in Singapore went offline, the user in Singapore would still be able to access the U.S. server.
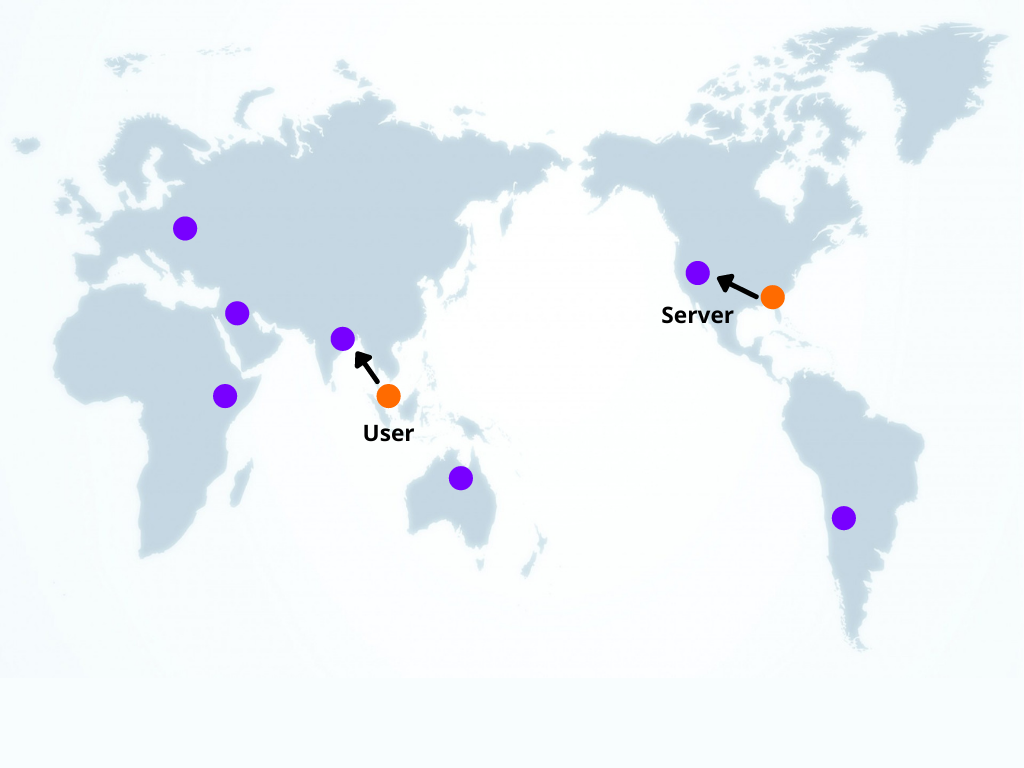
Many apps have more than 100 different server locations on the edge. However, multiple server locations can add significant cost. To make it cheaper and easier for developers to harness the power of the edge, many services offer the ability to easily deploy to the edge without having to spend a lot of money or time managing multiple servers. There are many different types of these. The most basic and widely used is an edge Content Delivery Network (CDN), which allows static content to be served from the edge. However, CDNs cannot do anything more complicated than serving content. If you need databases or custom code on the edge, you will need a more advanced service.
Introducing edge functions and edge databases
Luckily, there are solutions to this. The first of which, for running code on the edge, is edge functions. These are small pieces of code, automatically provisioned when needed, that are designed to respond to HTTP requests. They are also commonly called serverless functions. However, not all serverless functions run on the edge. Some edge function providers are Lambda@Edge, Cloudflare Workers, and Deno Deploy. In this article, we will focus on Cloudflare Workers. We can also take databases to the edge to ensure that our serverless functions run fast even when querying a database. There are also solutions for databases, the easiest of which is Fauna. With traditional databases, it is very hard or almost impossible to scale to multiple different regions. You have to manage different servers and how database updates are replicated between them. Fauna, however, abstracts all of that away, allowing you to use a cross-region database with a click of a button. It also provides an easy-to-use GraphQL interface and its own query language if you need more. By using Cloudflare Workers and Fauna, we can build a true edge app where everything is run on the edge.
Using Cloudflare Workers and Fauna to build a URL shortener
Setting up Cloudflare Workers and the code
URL Shorteners need to be fast, which makes Cloudflare Workers and Fauna perfect for this. To get started, clone the repository at github.com/AsyncBanana/url-shortener and set your directory to the folder generated.
git clone https://github.com/AsyncBanana/url-shortener.git
cd url-shortenerThen, install wrangler, the CLI needed for Cloudflare Workers. After that, install all npm dependencies.
npm install -g @cloudflare/wrangler
npm installThen, sign up for Cloudflare workers at https://dash.cloudflare.com/sign-up/workers and run wrangler login. Finally, to finish off the Cloudflare Workers set up, run wrangler whoami and take the account id from there and put it inside wrangler.toml, which is in the URL shortener.
Setting up Fauna
Good job, now we need to set up Fauna, which will provide the edge database for our URL shortener.
First, register for a Fauna account. Once you have finished that, create a new database by clicking “create database” on the dashboard. Enter URL-Shortener for the name, click classic for the region, and uncheck use demo data.

Once you create the database, click Collections on the dashboard sidebar and click “create new collection.” Name the collection URLs and click save.
Next, click the Security tab on the sidebar and click “New key.” Next, click Save on the modal and copy the resulting API key. You can also name the key, but it is not required. Finally, copy the key into the file named .env in the code under FAUNA_KEY.

API_KEY_HERE replaced with your keyGood job! Now we can start coding.
Create the URL shortener
There are two main folders in the code, public and src. The public folder is where all of the user-facing files are stored. src is the folder where the server code is. You can look through and edit the HTML, CSS, and client-side JavaScript if you want, but we will be focusing on the server-side code right now. If you look in src, you should see a file called urlManager.js. This is where our URL Shortening code will go.

First, we need to make the code to create shortened URLs. in the function createUrl, create a database query by running FaunaClient.query(). Now, we will use Fauna Query Language (FQL) to structure the query. Fauna Query Language is structured using functions, which are all available under q in this case. When you execute a query, you put all of the functions as arguments in FaunaClient.query(). Inside FaunaClient.query(), add:
q.Create(q.Collection("urls"),{
data: {
url: url
}
})What this does is creates a new document in the collection urls and puts in an object containing the URL to redirect to. Now, we need to get the id of the document so we can return it as a redirection point. First, to get the document id in the Fauna query, put q.Create in the second argument of q.Select, with the first argument being [“ref”,”id”]. This will get the id of the new document. Then, return the value returned by awaiting FaunaClient.query(). The function should now look like this:
return await FaunaClient.query(
q.Select(
["ref", "id"],
q.Create(q.Collection("urls"), {
data: {
url: url,
},
})
)
);
}Now, if you run wrangler dev and go to localhost:8787, you should see the URL shortener page. You can enter in a URL and click submit, and you should see another URL generated. However, if you go to that URL it will not do anything. Now we need to add the second part of this, the URL redirect.
Look back in urlManager.js. You should see a function called processUrl. In that function, put:
const res = await FaunaClient.query(q.Get(q.Ref(q.Collection("urls"), id)));What this does is executes a Fauna query that gets the value of the document in the collection URLs with the specified id. You can use this to get the URL of the id in the URL. Next return res.data.url.url.
const res = await FaunaClient.query(q.Get(q.Ref(q.Collection("urls"), id)));
return res.data.url.urlNow you should be all set! Just run wrangler publish, go to your workers.dev domain, and try it out!
Conclusion
Now have a URL shortener that runs entirely on the edge! If you want to add more features or learn more about Fauna or Cloudflare Workers, look below. I hope you have learned something from this, and thank you for reading.
Next steps
- Further improve the speed of your URL shortener by adding caching
- Add analytics
- Read more about Fauna
Read more about Cloudflare Workers